tl;dr: vector embeddings capture semantic meaning; cheap to compute, used in initial content ranking; good first quality indicator
Key facts:
- Vector embeddings encapsulate the meaning of your content
- Embeddings are extremely cheap to compute
- Therefore used in the initial content ranking for AI
- Should be viewed as an indicator rather than ground truth
Vector embeddings & cosine similarity are all the fuzz now in the AIO social sphere, so here is a quick explainer:
1. Vector embeddings explained (No PhD required)
Specialised AI models called encoder models read your content and compress its meaning into mathematical vectors (lists of numbers). Think of it as a massive neural network that is trained on billions of documents to summarise the entire content into a bunch of numbers, the vector space.
Here is how this looks like for a 2D vectors:
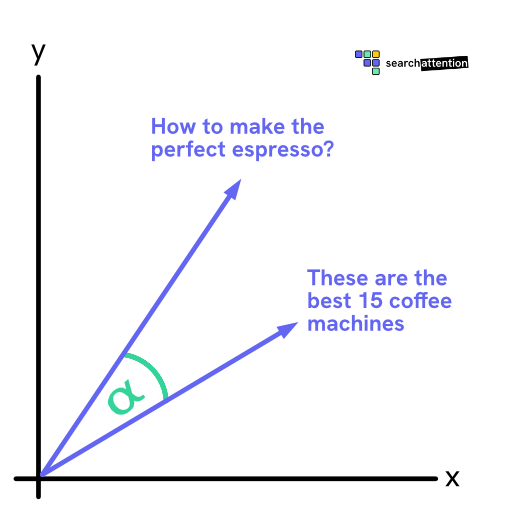
Content about the same topic cluster together in the vector space – even if they use completely different words.
Real example:
- ‘What is email marketing automation?’ → [0.34, 0.78]
- ‘Top 15 newsletter automation tools’ → [0.31, 0.82]
But how do we measure whether two vectors are similar?
This is where cosine similarity comes into play. Cosine similarity is a measure of the similarity between two vectors (0 to 1 score). If your article about ‘CRM software’ gets 0.89 similarity with the query ‘customer management tools’, you’re on the right track!
2. Where vector embeddings fail
Vector embeddings are fast and cheap – perfect for initial screening. But they have two major blind spots:
Problem #1: Terrible at exact keyword matching
- ‘iPhone 15’ vs ‘iPhone 16’ = almost identical embeddings
- ‘React developer’ vs ‘Vue developer’ = high similarity score
- ‘2023 data’ vs ‘2024 data’ = embeddings can’t tell the difference
That’s why AI systems typically pair embeddings with traditional keyword matching algorithms such as BM25.
Problem #2: Can’t validate search intent
Content embeddings are calculated independently of user queries. They don’t know:
- Whether your content actually answers the specific question
- If the user wants a tutorial vs comparison vs definition
- Whether your ‘beginner guide’ matches a ‘advanced techniques’ query
Enter rerankers: These AI models look at both your content and the specific query to determine: ‘Does this actually answer what the user asked?’
Modern AI search engines such as Perplexity therefore use a combination of embeddings, traditional matching algorithms and rerankers:
- Embeddings + BM25: Fast filtering for semantic + keyword relevance
- Rerankers: Expensive but precise – validates actual search intent match
3. How AI search uses vector embeddings
You may be shocked to hear that vector embeddings are not new, but have been used by Google as a ranking factor as early as 2019!
Computing embeddings is extremely fast and cheap. Using cosine similarity gives a good first estimate of whether the content is relevant to the search intent of the user.
AI search engines like Perplexity therefore use embeddings (alongside other ranking factors) to create an initial candidate set of content that is fed to the AI model to provide the final answer.
4. What this means for your AI optimisation strategy
For you as an AIO manager this means:
- Embeddings are an important indicator for AI search engines whether your content is relevant for the search intent
- Different AI search engines use multiple, different embeddings
- Cosine similarity values should, however, not be overstated
Summary
Vector embeddings are the semantic DNA of your content – AI compresses meaning into numbers that cluster similar topics together. While fast and cheap for initial screening, they fail at exact keywords and can’t validate search intent alone. Modern AI search uses embeddings + BM25 + rerankers for complete relevance matching. Bottom line: important relevance indicator, but don’t overstate cosine similarity scores.
Pro tip: You can check semantic similarity of your content with tools like searchattention.